Diff-in-Diff as an identification strategy

Parallel trend assumption (PTA)

Estimate Average Treatment Effect on the Treated (ATT)

But what if the PTA doesn't hold?

But what if the PTA doesn't hold?
We can potentially remove [part of] the bias by matching on Xsit=Xi

Sensitivity analysis for Diff-in-Diff
- In an event study null effects prior to the intervention:

Honest approach to test pretrends
One main issue with the previous test Underpowered
Rambachan & Roth (2023) propose sensitivity bounds to allow pre-trends violations:
- E.g. Violations in the post-intervention period can be at most times the max violation in the pre-intervention period.
S1 - No interaction between X and t

S2 - Equal interaction between X and t by treatment

S3 - Differential interaction between X and t by treatment

Why is this bias reduction important?
- Example of S2 (Quadratic) with no true effect:

Why is this bias reduction important?
- Even under modest bias, we would incorrectly reject the null 20% of the time.

Why is this bias reduction important?
- Sensitivity analysis results are skewed by the magnitude of the bias.

S4: Bias cancellation

Before matching: Household income


Before matching: Average SIMCE


Groups are balanced in specific characteristics

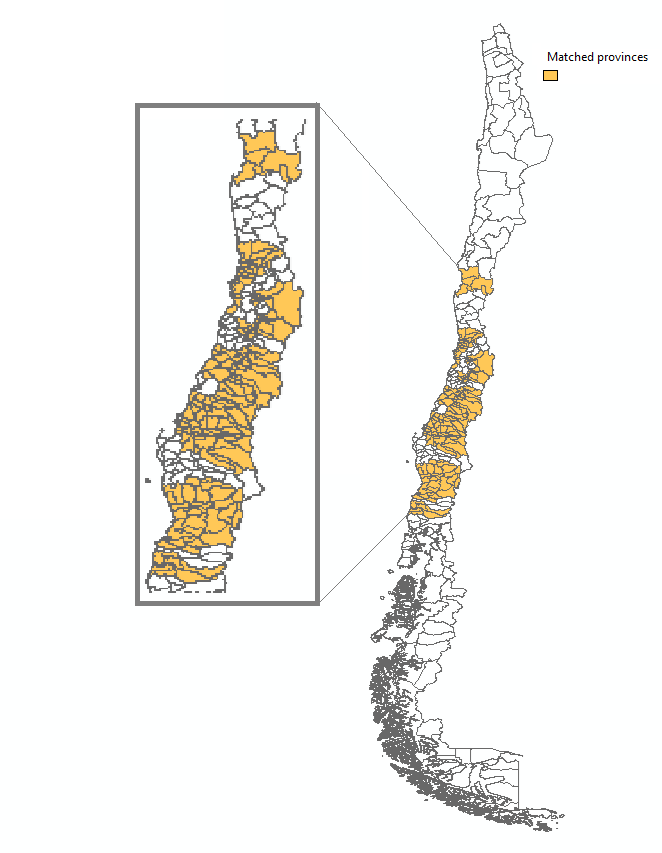
Matching in 16 out of 53 provinces
After matching: Household income


After matching: Average SIMCE


Potential reasons?
- Increase in probability of becoming SEP in 2009 jumps discontinuously at 60% of SEP student concentration in 2008 (4.7 pp; SE = 0.024)

Conclusions and Next Steps
- Matching can be an important tool to address violations in PTA.
- Bias reduction is very important for sensitivity analysis.
- Serial correlation also plays an important role: Don't match on random noise.
- Next steps: Partial identification using time-varying covariates

Honest approach to test pretrends
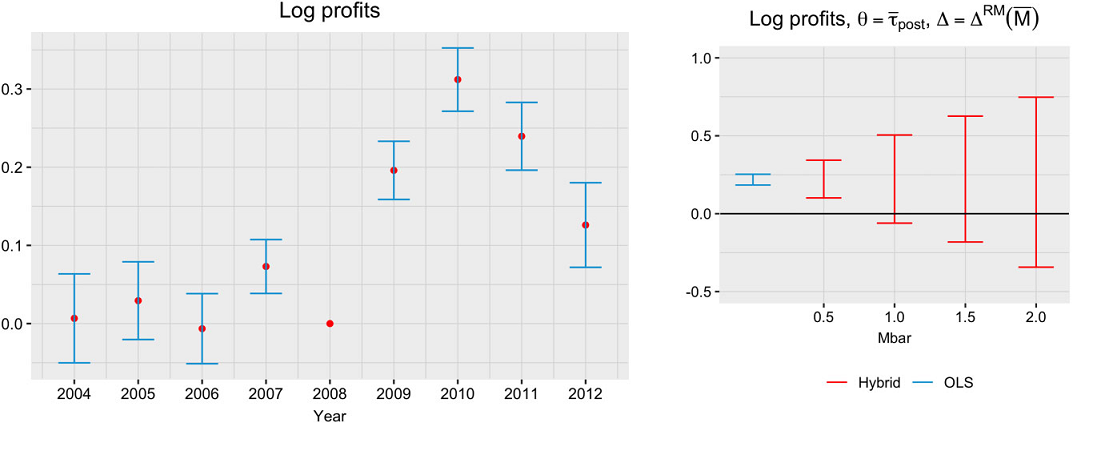
One drawback of the previous method is that it can overstate (or understate) the robustness of findings if the point estimate is biased.
- Honest CIs depend on the magnitude of the point estimate as well as the pre-trend violations.
- Honest CIs depend on the magnitude of the point estimate as well as the pre-trend violations.
Matching can reduce the overall bias of the point estimate

Data Generating Processes

SEP adoption over time
